10 Macromolecules
Overview
Macromolecules are giants of the atomic world. The prefix “macro-” means “very large scale.” Indeed, macromolecules dwarf other molecules involved in life’s chemistry, such as table salt (NaCl) or water (H2O). Macromolecules are typically comprised of at least 1,000 atoms, with repeated structures of smaller components. The process of polymerization links together the smaller components (monomers). It’s the extent of repetition that leads to large size.
It’s the large size of macromolecules that dictates their importance in living systems. They are the basis of complex cellular life. Macromolecules are not intrinsically stable. They are not created in the absence of life, nor can they persist for long outside living systems.
Essentially, a macromolecule is a single molecule that consists of many covalently linked subunit molecules. A polymer is a single molecule composed of similar monomers. In physiology, the four major macromolecules are:
- nucleic acids – made of nucleotide subunits linked through their phosphate backbone.
- proteins – made of amino acid subunits linked between carbon and nitrogen.
- lipids – typically large molecules comprised of nonpolar bonds, making them hydrophobic. Some lipids contain covalently attached polar groups, which may act as attachment points for multiple hydrophobic lipid molecules.
- carbohydrates – have covalently linked sugar groups.
So far, we have discussed the major elements and types of bonds that are important in the functioning of a cell. Together these elements and bonds define the major properties of the four classes of macromolecules that make up a cell: carbohydrates, proteins, lipids and nucleic acids. In this module, we will explore these macromolecules.
Carbohydrates, proteins and nucleic acids are all examples of polymers. Polymers are very large molecules composed of smaller units joined by covalent bonds using a common set of chemical reactions. Proteins are linear polymers of amino acids all joined by peptide bonds. Polysaccharides are the carbohydrates joined through glycosidic bonds in sometimes quite complex branched structures. DNA and RNA are polymers of nucleic acids linked by phosphodiester bonds. This module includes a discussion of the structures of these organic macromolecules.
Carbohydrates
The simplest of the macromolecules are carbohydrates, also called saccharides. The name is descriptive of the character of this class of molecules, since they all have the general formula of a hydrated carbon.
(C(H2O))n
This represents a 2:1 ratio of hydrogen to oxygen atoms(as in water)but in this case, they are attached to a carbon backbone. the constituent atoms of carbohydrates can be configured in virtually endless configurations, so carbohydrate molecules come in a multitude of different shapes and sizes.
Monosaccharides are the most basic units of carbohydrates. These are simple sugars, including glucose, fructose, and others. They contain between three and seven carbon atoms, have a sweet taste and are used by the body for energy.
Polysaccharides are long polymers of monosaccharide sugars that are covalently bonded together. Polysaccharides are often used to store the energy of the monosaccharide. These include starch (in plants) and glycogen (in humans and animals). Polysaccharides can also be used for structure in plants and other lower organisms. Carbohydrates are also critical components in the backbone of DNA, with one monosaccharide found in each nucleotide. With 3 billion DNA nucleotides per cell, that is a lot of monosaccharides in the body! Polysaccharides can be conjugated with other macromolecules. For example, complex carbohydrates can be linked with proteins or lipids to form glycoproteins and glycolipids, respectively.
Carbohydrates are best known as energy storage molecules. Their primary function is as a source of energy. Cells readily convert carbohydrates to usable energy. You will recall that molecules are a collection of atoms connected by covalent bonds. Table sugar, or sucrose, is the best-known carbohydrate. The most common carbohydrate in nature is glucose, which has the general formula (C(H2O))6 and which is a common source of energy for many living organisms.
However, the body does not need dietary carbohydrates for energy. Proteins and fats can meet the body’s needs, and the body can convert molecules into carbohydrates needed for energy and other cellular functions. But carbohydrates require minimal processing for use as energy. For example, a simple enzymatic reaction converts sucrose into blood sugar, which can be used directly as a source of cellular energy.
Proteins
After nucleic acids, proteins are the most important macromolecules. Structurally, proteins are the most complex macromolecules. A protein is a linear molecule comprised of amino acids. Twenty different amino acids are found in proteins. The sequence of a protein’s amino acids is determined by the sequence of bases in the DNA coding for the synthesis of this protein. A single protein molecule may be comprised of hundreds of amino acids. This sequence of amino acids is a protein’s primary structure. The protein’s size, shape and reactive properties depend on the number, type and sequence of amino acids. The amino acid chain can remain in its primary linear structure, but often it folds up and in on itself to form a shape. This secondary structure forms from localized interactions (hydrogen bonding) of amino acid side chains. These include alpha helix and beta sheet structures. The alpha helix is dominant in hemoglobin, which facilitates transport of oxygen in blood. Secondary structures are integrated along with twists and kinks into a three-dimensional protein. This functional form is called the tertiary structure of the protein. An additional level of organization results when several separate proteins combine to form a protein complex—called quaternary structure [1].
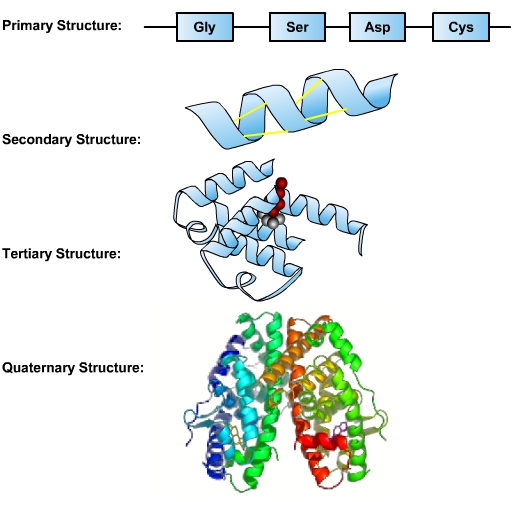
Proteins perform numerous essential functions within the cell. Many proteins serve as enzymes, which control the rate of chemical reactions, and hence the responsiveness of cells to external stimuli. An enzyme can fast-forward a reaction that would take millions of years under normal conditions and make it happen in just a few milliseconds. Enzymes are important in DNA replication, transcription and repair. Digestive processes are also largely facilitated by enzymes, which break down molecules that would otherwise be too large to be absorbed by the intestines. Enzymatic proteins also play a role in muscle contractions.
Other proteins are important in cell signaling and cell recognition. Receptor proteins recognize substances as foreign and initiate an immune response. Through cell signaling, proteins mediate cell growth and differentiation during development. Several important proteins provide mechanical support for the cell, scaffolding that helps the cell maintain its shape. Other proteins comprise much of the body’s connective tissue and structures such as hair and nails.
For protein production in cells the body needs amino acids, which we ingest. It seems a bit inefficient, but we eat proteins, break them down into amino acids, distribute the amino acids inside the body and then build up new proteins. Our cells can synthesize some amino acids from similar ones, but essential amino acids must be obtained from the diet, since they cannot be synthesized. Deficiencies of protein in the diet result in malnutrition diseases such as kwashiorkor, which is common in developing countries. In cases of kwashiorkor, protein deficiency causes edema (swelling) which leads to a distended abdomen. Proteins are eventually metabolized into ammonia and urea, which are excreted by the kidneys. Kidney disease can cause these waste products to accumulate in the body, causing someone to become very ill, ultimately leading to death. A low protein diet can help those whose kidneys have a low level of function.
Unlike nucleic acids, which must remain unchanged in the body for the life of the organism, proteins are meant to be transient—they are produced, do their functions and then are recycled. Proteins are also readily denatured (unfolding of the secondary and tertiary structures) by extremes of heat or pH. When you boil an egg, the yolk and white stiffen and change color. When you cook meat, the flesh changes color and becomes firm. These changes arise because the constituent proteins denature, changing the properties of the tissues.
Amino Acids
Amino acids are the building blocks of proteins. The sequence of amino acids in individual proteins is encoded in the DNA of the cell. The physical and chemical properties of the 20 different naturally occurring amino acids dictate the shape of the protein and its interactions with its environment. Certain short sequences of amino acids in the protein also dictate where the protein resides in the cell. Proteins are composed of hundreds to thousands of amino acids. As you can imagine, protein folding is a complicated process and there are many potential shapes due to the large number of combinations of amino acids. By understanding the properties of the amino acids you will gain an appreciation for the limits of protein folding and will learn how to predict the potential higher-order structure of the protein.
All amino acids have the same backbone structure, with an amino group (the α-amino, or alpha-amino, group), a carboxyl group, an α-hydrogen, and a variety of functional groups (R) all attached to the α-carbon.
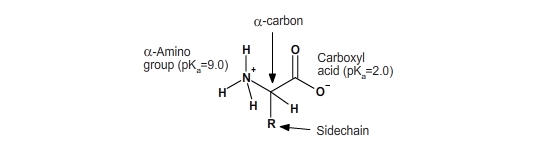
If all of the amino acids have the same basic structure with an amino, a carboxyl and a hydrogen fixed to the alpha-carbon, then the large variation in the properties and structure of the amino acids must come from the fourth group attached to the alpha carbon. This group is referred to as the side chain of the amino acid or the R group. The side-chain groups of amino acids contain many common groups of atoms called functional groups. The majority of functional groups, such as the hydroxyl group (–OH), are commonly polar, allowing them to interact with water. Functional groups can be neutral or charged. Functional groups can be acidic, neutral, or basic.
Peptide Bonds
Proteins are polymers of amino acids. The amino acids are joined together by a condensation reaction. Each amino acid in the polymer is referred to as a “residue.” Individual amino acids are joined together by the attachment of the nitrogen of an amino group of one amino acid to the carbonyl carbon (C=O) of the carboxyl group of another amino acid, to create a covalent peptide bond and yield a molecule of water, as shown below.
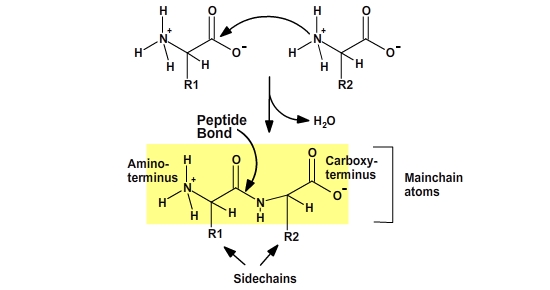
The resulting peptide chain is linear with defined ends. Short polymers (less than 50 residues or amino acids) are usually referred to as peptides, and longer polymers as polypeptides. Several polypeptides together can form some large proteins. Because the synthesis takes place from the alpha-amino group of one amino acid to the carboxyl group of another amino acid, the result is that there will always be a free amino group on one end of the growing polymer (the N-terminus) and a free carboxyl group on the other end (the C-terminus).
Note that after the amino acid has been incorporated into the protein, the charges on the amino and carboxy termini have disappeared, thus the main-chain atoms have become polar functional groups. Since each residue in a protein has exactly the same main-chain atoms, the functional properties of a protein must arise from the different side-chain groups.
By convention, the sequences of peptides and proteins are written with the N-terminus on the left and the C-terminus on the right. The name of the N-terminal residue is always the first amino acid. The name of each amino acid then follows. The primary sequence of a protein refers to its amino acid sequence.
Nucleic Acids
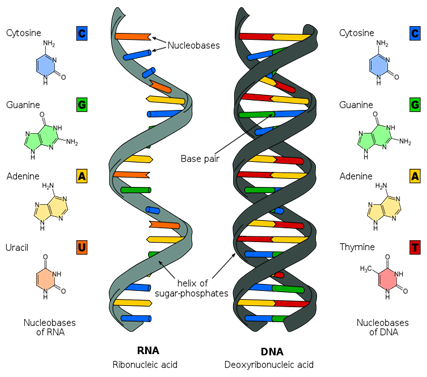
Primarily located in the cell nucleus (hence the name) nucleic acids are replicating macromolecules. The most important are DNA and RNA. Without them, cells could not replicate, making life impossible. These molecules store the cell’s “software”—the instructions that govern its function, processes and structure. The code is comprised of sequences of four bases—adenine, cytosine, guanine and thymine (uracil in RNA). These are arranged in sets of three called triplets. Each triplet specifies an amino acid, which in turn is a component of a protein macromolecule. All the intricate complexity of the human body arises from the information encoded by just four chemicals in a single long DNA macromolecule.
In humans, mistakes in the structures of DNA and RNA cause diseases, including sickle cell anemia, hemophilia, Huntingdon’s chorea and some types of cancer. Even a small error can result in a dramatic effect. Sickle cell disease is caused when just one amino acid in the DNA base sequence is changed. Through directing chemical processes, nucleic acids instruct cells how to differentiate into various organs. During development, whole sets of DNA sequences are shut down or activated to drive specific processes. These processes lead to different kinds of cells that form organs such as the heart, liver, skin and brain.
Within the cell, nucleic acids are in turn organized into higher-level structures called chromosomes. You can see chromosomes with a light microscope, using an appropriate stain. Early study of chromosomes helped scientists discover and understand the role of nucleic acids in cellular reproduction. Errors in chromosomal structure lead to malfunctions of life processes. For example, in humans, an extra chromosome 21 results in Down Syndrome.
The Backbone[2]:
Our genetic code is determined by only four bases in DNA (G, C, A, T), which are repeated and arranged in a special order. For example,
1 agccctccag gacaggctgc atcagaagag gccatcaagc agatcactgt ccttctgcca
61 tggccctgtg gatgcgcctc ctgcccctgc tggcgctgct ggccctctgg ggacctgacc
121 cagccgcagc ctttgtgaac caacacctgt gcggctcaca cctggtggaa gctctctacc
DNA is organized into a linear polymer in a double helix and maintains the inherited order of bases or genetic code. The “steps” of the DNA ladder have the code that ultimately directs the synthesis of our proteins. This linear polymer of genetic code is maintained when double strand DNA is transcribed to single strand RNA.
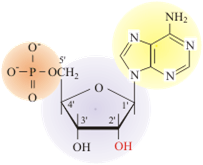
The fundamental unit of DNA is the nucleotide. The nucleotide contains a phosphate group (shown in orange), which will eventually give the DNA polymer its charge and interconnect nucleotides on the backbone. The furanose sugar group is a five-sided sugar (shown in purple). The nitrogenous base (shown in yellow) determines the type of nucleotide formed.
The major difference in the polymer backbones between DNA and RNA is the sugar used in the formation of the polymer. In DNA (DeoxyriboNucleic Acid) the 2′ position of the furanose has a hydrogen. In RNA (RiboNucleic Acid), the 2′ position of the furanose has an OH (hydroxyl) and the sugar is the monosaccharide ribose in the furanose conformation.
The DNA double helix is held in place with the hydrogen bonding of purines to pyrimidines. Recall that hydrogen bonds are weak interactions, not like the covalent bonds of the phosphate-furanose backbone. Thus, DNA is held together, but can be pulled apart for transcription to RNA or for DNA replication.
DNA Transcription
DNA replication: Every time a cell divides, all of the DNA of the genome is duplicated (called replication) so that each cell after the division (called a daughter cell) has the same DNA as the original cell (called the mother cell).

DNA transcription: For the genetic code to become a protein, it goes through a transcription step. DNA is transcribed into RNA (a single-strand nucleic acid). The RNA is then shuttled away from the DNA to the region of protein synthesis.

RNA translation: RNA is translated from a nucleic acid code into the amino acid sequence of a protein.

Thus, the DNA gene code is able to duplicate to maintain consistency throughout the person’s body and throughout the person’s life. DNA is also used to make proteins through the use of an RNA intermediate.
Lipids
Lipids include fats and waxes. Several vitamins, such as A, D, E and K, are lipid soluble. Perhaps the most important role of lipids is in forming the membranes of cells and organelles. In this way, lipids enable isolation and control of chemical processes. They also play a role in energy storage and cell signaling.
Lipid molecules forming cell membranes are comprised of a hydrophilic “head” and hydrophobic “tail.” A phospholipid bilayer is formed when the two layers of phospholipid molecules organize with the hydrophobic tails meeting in the middle. Scientists believe that the formation of cell-like globules of lipids was a vital precursor to the origin of cellular life, since membranes physically separate intracellular components from the extracellular environment. Thus, lipid membranes enclose other macromolecules, confine volumes to increase the possibility of reaction, and protect chemical processes. Proteins with hydrophobic regions float within the lipid bilayer. These molecules govern transport of charged or lipophobic molecules in and out of the cell, such as energy molecules and waste products. Some of these lipids also have attached carbohydrate molecules jutting out of the membrane are important for cell recognition as mentioned previously.
Lipids are also vital energy storage molecules. Carbohydrates can be used right away, and lipids provide long-term energy storage. Lipids accumulate in adipose cells (fat cells) in the body. As part of the catabolic process, from the days when humans had to forage for food, excess carbohydrates can be converted into lipids, which are then stored in fatty tissue. Ultimately, too many ingested carbohydrates and lipids lead to obesity.
- Image: Protein Structures, Image description: The primary structure is the sequence of amino acids that make up the polypeptide chain. The secondary structure is maintained by hydrogen bonds between amino acids in different regions of the original strand. The tertiary structure occurs as a result of further folding and bonding of the secondary structure, and is the functional form of the protein. The quaternary structure is formed as a result of interactions between two or more tertiary polypeptide chains. ↵
- Image: Structure of RNA and DNA, Image description: The nucleobases of Ribonucleic acid (RNA) are adenine, cytosine, guanine, and uracil. The nucleobases of Deoxyribonucleic acid (DNA) are adenine, cytosine, guanine, and thymine. RNA consists of a single strand with a sugar-phosphate backbone, while DNA has two sugar-phosphate backbones, which twist to form its characteristic double helix shape. ↵
