5.3: Mean and Variance of a Discrete Random Variable
Learning Objective
- Find the mean and variance of a discrete random variable, and apply these concepts to solve real-world problems.
In the Exploratory Data Analysis (EDA) section, we displayed the distribution of one quantitative variable with a histogram, and supplemented it with numerical measures of center and spread. We are doing the same thing here. We display the probability distribution of a discrete random variable with a table, formula or histogram, and supplement it with numerical measures of the center and spread of the probability distribution. These measures are the mean and standard deviation of the random variable.
This section will be devoted to introducing these measures. As before, we’ll start with the numerical measure of center, the mean. Let’s begin by revisiting an example we saw in EDA.
World Cup Soccer
Recall that we used the following data from 3 World Cup tournaments (a total of 192 games) to introduce the idea of a weighted average.
We’ve added a third column to our table that gives us relative frequencies.
| total # goals/game | frequency | relative frequency |
|---|---|---|
| 0 | 17 | 17 / 192 = .089 |
| 1 | 45 | 45 / 192 = .234 |
| 2 | 51 | 51 / 192 = .266 |
| 3 | 37 | 37 / 192 = .193 |
| 4 | 25 | 25 / 192 = .130 |
| 5 | 11 | 11 / 192 = .057 |
| 6 | 3 | 3 / 192 = .016 |
| 7 | 2 | 2 / 192 = .010 |
| 8 | 1 | 1 / 192 = .005 |
| the mean for this data | = | [latex]\frac{0\left(17\right)+1\left(45\right)+2\left(51\right)+3\left(37\right)+4\left(25\right)+5\left(11\right)+6\left(3\right)+7\left(2\right)+8\left(1\right)}{192}[/latex] |
| distributing the division by 192 we get: | = | [latex]0\left(\frac{17}{192}\right)+1\left(\frac{45}{192}\right)+2\left(\frac{51}{192}\right)+3\left(\frac{37}{192}\right)+4\left(\frac{25}{192}\right)+5\left(\frac{11}{192}\right)+6\left(\frac{3}{192}\right)+7\left(\frac{2}{192}\right)+8\left(\frac{1}{192}\right)[/latex] |
Notice that the mean is each number of goals per game multiplied by its relative frequency. Since we usually write the relative frequencies as decimals, we can see that:
| mean number of goals per game | = | 0(.089) + 1(.234) + 2(.266) + 3(.193) + 4(.130) + 5(.057) + 6(.016) + 7(.010) + 8(.005) |
| = | 2.36, rounded to two decimal places |
Mean of a Random Variable
In Exploratory Data Analysis, we used the mean of a sample of quantitative values—their arithmetic average—to tell the center of their distribution. We also saw how a weighted mean was used when we had a frequency table. These frequencies can be changed to relative frequencies. So we are essentially using the relative frequency approach to find probabilities. We can use this to find the mean, or center, of a probability distribution for a random variable by reporting its mean, which will be a weighted average of its values; the more probable a value is, the more weight it gets. As always, it is important to distinguish between a concrete sample of observed values for a variable versus an abstract population of all values taken by a random variable in the long run.
Whereas we denoted the mean of a sample as [latex]\bar{x}[/latex], we now denote the mean of a random variable as [latex]\mu_{x}[/latex]. Let’s see how this is done by looking at a specific example.
Example
Xavier’s Production Line
Xavier’s production line produces a variable number of defective parts in an hour, with probabilities shown in this table:
.\" The data in columns (X: P(X=x)): 0: .15; 1: .30; 2: .25; 3: .20; 4: .10;")
How many defective parts are typically produced in an hour on Xavier’s production line? If we sum up the possible values of X, each weighted with its probability, we have
[latex]\mu_{x}=0(0.15)+1(0.30)+2(0.25)+3(0.20)+4(0.10)=1.8[/latex]
Here is the general definition of the mean of a discrete random variable:
- mean of a discrete random variable
-
In general, for any discrete random variable X with probability distribution

\". Here is the data in the table, given in column format (X: P(X=x)): x_1: p_1; x_2: p_2; x_3: p_3; ... x_n: p_n;") the mean of X is defined to be[latex]\mu x=x_{1}p_{1}+x_{2}p_{2}+...+x_{n}p_{n}=\sum_{i=1}^{n}x_{i}p_{i}[/latex]
the mean of X is defined to be[latex]\mu x=x_{1}p_{1}+x_{2}p_{2}+...+x_{n}p_{n}=\sum_{i=1}^{n}x_{i}p_{i}[/latex]
In general, the mean of a random variable tells us its “long-run” average value. It is sometimes referred to as the expected value of the random variable. But this expression may be somewhat misleading, because in many cases it is impossible for a random variable to actually equal its expected value. For example, the mean number of goals for a World Cup soccer game is 2.36. But we can never expect any single game to result in 2.36 goals, since it is not possible to score a fraction of a goal. Rather, 2.36 is the long-run average of all World Cup soccer games. In the case of Xavier’s production line, the mean number of defective parts produced in an hour is 1.8. But the actual number of defective parts produced in any given hour can never equal 1.8, since it must take whole number values.
To get a better feel for the mean of a random variable, let’s extend the defective parts example:
In general, the mean of a random variable tells us its “long-run” average value. It is sometimes referred to as the expected value of the random variable. But this expression may be somewhat misleading, because in many cases it is impossible for a random variable to actually equal its expected value. For example, the mean number of goals for a World Cup soccer game is 2.36. But we can never expect any single game to result in 2.36 goals, since it is not possible to score a fraction of a goal. Rather, 2.36 is the long-run average of all World Cup soccer games. In the case of Xavier’s production line, the mean number of defective parts produced in an hour is 1.8. But the actual number of defective parts produced in any given hour can never equal 1.8, since it must take whole number values.
To get a better feel for the mean of a random variable, let’s extend the defective parts example:
Example
Xavier’s and Yves’ Production Lines
Recall the probability distribution of the random variable X, representing the number of defective parts in an hour produced by Xavier’s production line.
The number of defective parts produced each hour by Yves’ production line is a random variable Y with the following probability distribution:
.\" The data in column format (Y: P(Y=y)): 0: .05; 1: .05; 2: .10; 3: .75; 4: .05;")
Look at both probability distributions. Both X and Y take the same possible values (0, 1, 2, 3, 4).
However, they are very different in the way the probability is distributed among these values.
Did I get this?
Did I get this?
Here again is the probability distribution of Y, the number of defective parts in an hour in Yves’ production line:
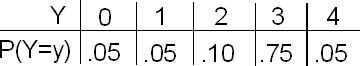
Applications of the Mean
Means of random variables are useful for telling us about long-run gains in sales, or for insurance companies.
Here are two examples:
Example
Pizza Delivery #1
Your favorite pizza place delivers only one kind of pizza, which is sold for $10, and costs the pizza place $6 to make. The pizza place has the following policy regarding delivery: if the pizza takes longer than half an hour to arrive, there is no charge. Let the random variable X be the pizza place’s gain for any one pizza.
Experience has shown that delivery takes longer than half an hour only 10 percent of the time.
Find the mean gain per pizza, [latex]\mu_{x}[/latex].
In order to find the mean of X, we first need to establish its probability distribution—the possible values and their probabilities.
The random variable X has two possible values: either the pizza costs them $6 to make and they sell it for $10, in which case X takes the value $10 – $6 = $4, or it costs them $6 to make and they give it away, in which case X takes the value $0 – $6 = -$6. The probability of the latter case is given to be 10 percent, or .1, so using complements, the former has probability .9. Here, then is the probability distribution of X:
.\" Here is the data in columns (X: P(X=x)): +4: .9; -6: .1; In other words, when pizza delivery is not longer than half an hour, X = +4, and P(X = +4) = .9 . When pizza delivery takes longer than half an hour, X=-6, and P(X = -6) = .1 .")
Therefore, [latex]\mu _{x}=(+4)(.9)+(-6)(.1)=+3[/latex]
In the long run, the pizza place gains an average of $3 per pizza delivered.
Example
Pizza Delivery #2
If the pizza place wants to increase its mean gain per pizza to $3.90, how much should it raise the price from $10? We need to replace the original cost of 10 with an as-yet-to-be-determined new cost N, resulting in this probability distribution table:
.\" Here is the data in columns (X: P(X=x)): N-6: .9; -6: .1; In other words, when pizza delivery is not longer than half an hour, X = N-6, and P(X = N-6) = .9 . When pizza delivery takes longer than half an hour, X=-6, and P(X = -6) = .1 .")
Next, setting [latex]\mu_{x}[/latex] equal to +3.90 instead of +3, we solve
[latex]3.9=(N-6)(.9)+(-6)(.1)=.9N-6[/latex] or
[latex].9N=9.9[/latex]
Therefore, the new price must be 11 dollars.
Did I get this?
Example
Raffle
In order to raise money, a charity decides to raffle off some prizes. The charity sells 2,000 raffle tickets for $5 each. The prizes are:
- 10 movie packages (two tickets plus popcorn) worth $25 each
- 5 dinners for two worth $50 each
- 2 smart phones worth $200 each
- 1 flat-screen TV worth $1,500
What is the expected gain or loss if you buy a single raffle ticket? The expected value can be written as E(X).
There are 5 possible outcomes when you buy a ticket: win movie package, win dinner for two, win smart phone, win TV, win nothing.
| prize | net gain or loss | probability |
|---|---|---|
| movie package | 25 – 5 | 10 / 2000 |
| dinner for two | 50 – 5 | 5 / 2000 |
| smart phone | 200 – 5 | 2 / 2000 |
| TV | 1500 – 5 | 1 / 2000 |
| nothing | 0 – 5 | (2000 – 10 – 5 – 2 – 1) / 2000 |
The previous information is summarized below in a probability distribution:
.\" Here is the data in column oriented format (X: P(X=x), comment): 20: 10/20000 (movie package); 45: 5/2000 (dinner for two); 195: 2/2000 (smart phone); 1495: 1/2000 (TV); -5: 1982/2000 (Nothing);")
[latex]E\left ( X \right )=\frac{-7600}{2000}=3.80\mu_{x}=E\left ( X \right )=20\left ( \frac{10}{2000} \right )+\left ( \frac{5}{2000} \right )+195\left ( \frac{2}{2000} \right )+1495\left ( \frac{1}{2000} \right )+\left ( -5 \right )\left ( \frac{1982}{2000} \right )[/latex]
[latex]E\left ( X \right )=\frac{-7600}{2000}=3.80[/latex]
Since we got a negative number, we have an expected loss of $3.80 for each raffle ticket purchased. Recall that this is based upon a long-run average.
Each raffle ticket has only 5 possible outcomes:
-
$20 net gain if you win the movie package
-
$45 net gain if you win the dinner for two
-
$195 net gain if you win the smart phone
-
$1,495 net gain if you win the TV
-
$5 net loss if you do not win a prize
It should not be surprising that you have an expected loss. After all, the charity’s goal is to raise money. If you have an expected loss of $3.80 per ticket, they will have an expected gain of $3.80 per ticket. Each ticket gives the charity +5 (it was -5 for you). The prizes are reversed, too. For example, the movie package is -20 + 5 for the charity (it was 20 – 5 for you).
Here is another example:
Example
Life Insurance #1
Suppose you work for an insurance company, and you sell a $100,000 whole-life insurance policy at an annual premium of $1,200. (This means that the person who bought this policy pays $1,200 per year so that in the event that he or she dies, the policy beneficiaries will get $100,000). Actuarial tables show that the probability of death during the next year for a person of your customer’s age, sex, health, etc. is .005. Let the random variable X be the company’s gain from such a policy.
What is the expected or mean gain (amount of money made by the company) for a policy of this type?
In other words, we need to find [latex]\mu _{x}[/latex].
Since this is a whole-life policy, there are two possibilities here; either the customer dies this year (which you are given will happen with probability .005), or the customer does not die this year (which, by the complement rule, must be .995).
In both cases, the company gets the $1,200 premium. If the customer lives, the company just gains the $1,200, but if the customer dies, the company needs to pay $100,000 to the customer’s beneficiaries. Therefore, here is the probability distribution of X:
\". Here is the data in column oriented format (X: P(X=x), comment): +1200: .995 (live); 1200-100,000: .005 (die);")
Their average, or expected, gain overall is
[latex]\mu _{x}[/latex] = 1200(.995) + (1200 – 100,000)(.005) = 700 dollars.
Example
Life Insurance #2
Suppose that five years have passed and your actuarial tables indicate that the probability of death during the next year for a person of your customer’s current age has gone up to .0075. Obviously, this change in probability should be reflected in the annual premium (since it is slightly more risky for the insurance company to insure the customer).
What should the annual premium be (instead of $1,200) if the company wants to keep the same expected gain?
Now we substitute .0075 for .005, replace 1,200 with an unknown new premium N, and set the mean gain equal to 700, as it was before:
\". Here is the data in column oriented format (X: P(X=x), comment): N: .9925 (live); N-100,000: .0075 (die);")
| We need to solve: | 700 | = | (N)(.9925) + (N – 100,000)(.0075) |
| Using some algebra: | 700 | = | N – 750 |
| Finally | N | = | 1450 |
In order to keep the same expected gain of $700, the company should increase that customer’s premium to $1,450.
The purpose of this next activity is to give you guided practice in solving practical problems whose solution is based on the mean of random variables.
Did I get this?
Variance and Standard Deviation of a Discrete Random Variable
In Exploratory Data Analysis, we used the mean of a sample of quantitative values (their arithmetic average, [latex]\bar{x}[/latex]) to tell the center of their distribution, and the standard deviation (s) to tell the typical distance of sample values from their mean. We described the center of a probability distribution for a random variable by reporting its mean [latex]\mu _{x}[/latex], and now we would like to establish an accompanying measure of spread. Our measure of spread will still report the typical distance of values from their means, but in order to distinguish the spread of a population of all of a random variable’s values from the spread (s) of sample values, we will denote the standard deviation of the random variable X with the Greek lower case “sigma,” and use a subscript to remind us what is the variable of interest (there may be more than one in later problems):
Notation: [latex]\sigma _{X}[/latex]
We will also focus more frequently than before on the squared standard deviation, called the variance, because some important rules we need to invoke are in terms of variance [latex]\sigma _{X}^{2}[/latex] rather than standard deviation [latex]\sigma _{X}[/latex].
Example
Xavier’s Production Line
Recall that the number of defective parts produced each hour by Xavier’s production line is a random variable X with the following probability distribution:
We found the mean number of defective parts produced per hour to be [latex]\mu _{x}[/latex] = 1.8. Obviously, there is variation about this mean: some hours as few as 0 defective parts are produced, whereas in other hours as many as 4 are produced. Typically, how far does the number of defective parts fall from the mean of 1.8? As we did for the spread of sample values, we measure the spread of a random variable by calculating the square root of the average squared deviation from the mean. Now “average” is a weighted average, where more probable values of the random variable are accordingly given more weight. Let’s begin with the variance, or average squared deviation from the mean, and then take its square root to find the standard deviation:
, Sq. deviation = (0-1.8)², and P(X=0) = .15 . For X=1, Dev. from mean = (1-1.8), Sq. deviation = (1-1.8)², and P(X=1) = .30. For X=2, Dev. from mean = (2-1.8), Sq. deviations = (2-1.8)², and P(X=2) = .25 . For X=3, Dev. from mean = (3-1.8), Sq. deviations = (3-1.8)², and P(X=3) = .20 . For X=4, Dev. from mean = (4-1.8), Sq. deviations = (4-1.8)², and P(X=4) = .10 .")
Variance = [latex]\sigma ^{2}_{X}=(0-1.8)^{2}(0.15)+(1-1.8)^{2}(0.30)+(2-1.8)^{2}(0.25)+(3-1.8)^{2}(0.20)+(4-1.8)^{2}(0.1)=1.46[/latex]
standard deviation = [latex]\sigma _{X}=\sqrt{1.46}=1.21[/latex]
How do we interpret the standard deviation of X?
Xavier’s production line produces an average of 1.80 defective parts per hour. The number of defective parts varies from hour to hour; typically (or, on average), it is about 1.21 away from 1.80.
Here is the formal definition:
- standard deviation of a discrete random variable
-
For any discrete random variable X with a probability distribution of
the variance of X is defined to be [latex]\sigma _{X}^{2}=(x_{1}-\mu _{X})^{2}p_{1}+(x_{2}-\mu _{X})^{2}p_{2}+...+(x_{n}-\mu _{X})^{2}p_{n}=\sum_{i=1}^{n}(x_{i}-\mu _{X})p_{i}[/latex]
and the standard deviation is [latex]\sigma _{X}=\sqrt{\sigma ^{2}_{X}}[/latex]
Did I get this?
Here again is the probability distribution of Y—the number of defective parts in an hour in Yves’ production line:
Review the following expressions to answer the question below:
The purpose of the next activity is to give you better intuition about the mean and standard deviation of a random variable.
Did I get this?
Keeping in mind that the mean describes where a histogram is centered, and the standard deviation describes spread by reporting the typical distance of values from their mean, compare the histograms in the four exercises here and match each to the correct combination of mean and standard deviation.




The concept of standard deviation is a bit harder to grasp than that of the mean. The purpose of the following examples and activities is to help you gain a better feel for the standard deviation of a random variable:
Example
Xavier’s and Yves’ Production Lines
Recall the probability distribution of the random variable X, representing the number of defective parts per hour produced by Xavier’s production line, and the probability distribution of the random variable Y, representing the number of defective parts per hour produced by Yves’ production line:
.\" The data in column format (X: P(X=x)): 0: .15; 1: .30; 2: .25; 3: .20; 4: .10; The second table also has two rows, labeled \"Y\" and \"P(Y=y).\" The data in column format (Y: P(Y=y)): 0: .05; 1: .05; 2: .10; 3: .75; 4: .05;")
Look carefully at both probability distributions. Both X and Y take the same possible values (0, 1, 2, 3, 4). However, they are very different in the way the probability is distributed among these values. We saw before that this makes a difference in means:
μX=1.8
μY=2.7
We now want to get a sense about how the different probability distributions impact their standard deviations.
Recall that the standard deviation of a random variable can be interpreted as a typical (or the long-run average) distance between the value of X and its mean.
So, 75% of the time Y will assume a value (3) that is very close to its mean (2.7), while X will assume a value (2) that is close to its mean (1.8) much less often—only 25% of the time. The long-run average, then, of the distance between the values of Y and their mean will be much smaller than the long-run average of the distance between the values of X and their mean.
Therefore, σY<σX=1.21 Actually, σY=0.85, so we can draw the following conclusion:
Yves’ production line produces an average of 2.70 defective parts per hour. The number of defective parts varies from hour to hour; typically (or, on average), it is about .85 away from 2.70.
Summary
Here are the histograms for the production lines:


When we compare distributions, the distribution in which it is more likely to find values that are further from the mean will have a larger standard deviation. Likewise, the distribution in which it is less likely to find values that are further from the mean will have the smaller standard deviation.
Did I get this?
The following graphs will be used in the next “Did I Get This?” exercise.
: 1: .07; 2: .10; 3: .12; 4: .13; 5: .16; 6: .13; 7: .12; 8: .10; 9: .07;")
: 1: .02; 2: .08; 3: .10; 4: .15; 5: .30; 6: .15; 7: .10; 8: .08; 9: .02;")
: 1: .01; 2: .01; 3: .10; 4: .18; 5: .40; 6: .18; 7: .10; 8: .01; 9: .01;")
: 1: .01; 2: .01; 3: .02; 4: .11; 5: .70; 6: .11; 7: .02; 8: .01; 9: .01;")
Did I get this?
Comment
As we have stated before, using the mean and standard deviation gives us another way to assess which values of a random variable are unusual. Any values of a random variable that fall within 2 standard deviations of the mean would be considered ordinary (not unusual).
Example
Xavier’s Production Line—Unusual or Not?
Looking once again at the probability distribution for Xavier’s production line:
Would it be considered unusual to have 4 defective parts per hour?
We know that μX=1.8 and σX=1.21.
Ordinary values are within 2 standard deviations of the mean. 1.8 – 2(1.21) = -.62 and 1.8 + 2(1.21) = 4.22. This gives us an interval from -.62 to 4.22. Since we cannot have a negative number of defective parts, the interval is essentially from 0 to 4.22. Because 4 is within this interval, it would be considered ordinary. Therefore, it is not unusual.
Would it be considered unusual to have no defective parts? Zero is within 2 standard deviations of the mean, so it would not be considered unusual to have no defective parts.
The following activity will reinforce this idea.
Did I get this?
Recall the probability distribution for changing majors.
We have made the following calculations for the mean and standard deviation. For some extra practice, feel free to verify our calculations.
μX=1.23 and σX=1.08
“Risk” in investments provides a useful application for the concept of variability. If there is no variability at all in possible outcomes, then the outcome is something we can count on, with no risk involved. At the other extreme, if there is a large amount of variability with possibilities for either tremendous loss or gain, then the associated risk is quite high.
If a variable’s possible values just differ somewhat, with some only marginally favorable and others unfavorable, then the underlying random experiment entails just a moderate amount of risk. The following example demonstrates how differing values of standard deviation reflect the amount of risk in a situation.
Example
Comparing Investments
Consider three possible investments, with returns denoted as X, Y, and Z, respectively, and probability distributions outlined in the tables below.
.\" The data in column format (X: P(X=x)): 14,000: 1; In other words, X only has one value, 14,000, and P(X=14,000) = 1.")
Investment X is what we’d call a “sure thing,” with a guaranteed return of $14,000: there is no risk involved at all.
.\" The data in column format (Y: P(Y=y)): 0: .98; 1,000,000: .02; In other words, P(Y = 0) = .98 and P(Y = 1,000,000) = .02")
Investment Y is extremely risky, with a high probability (.98) of no gain at all, contrasted by a slight probability (.02) of “making a killing” with a return of a million dollars.
.\" The data in column format (Y: P(Z=z)): 10,000: .5; 20,000: .5; In other words, P(Z = 10,000) = .5 and P(Z = 20,000) = .5")
Investment Z is somewhere in between: there is an equal chance for either a return that’s on the low side or a return that’s on the high side.
If you only consider the mean return on each investment, would you prefer X, Y, or Z? The means for X, Y, and Z are calculated as follows:
[latex]\mu _{X} = 14000(1)=14000[/latex]
[latex]\mu _{Y} = 0(0.98)+1000000(.02)=20000[/latex]
[latex]\mu _{Z} = 10000(0.5)+20000(0.5)=15000[/latex]
Clearly, the mean return for Y is highest, and so investment in Y would seem to be preferable.
Now consider the standard deviations, and consider which investment you’d prefer—X, Y, or Z.
The standard deviations are:
[latex]\sigma _{X}^{2}=(14000-14000)^{2}(1)=0[/latex]
[latex]\sigma _{X}=0[/latex]
[latex]\sigma _{Y}^{2}=(0-20000)^{2}(0.98)+(1,000,000-20000)^{2}(0.2)=1.96\times 10^{10}[/latex]
[latex]\sigma _{Y}=140,000[/latex]
[latex]\sigma _{Z}^{2}=(10000-15000)^{2}(0.5)+(20000-15000)^{2}(0.5)=25,000,000[/latex]
[latex]\sigma _{Z}=5000[/latex]
Granted, the mean returns suggest that investment X is least profitable and investment Y is most profitable. On the other hand, the standard deviations are telling us that the return for X is a sure thing; for Y, the remote chance of making a huge profit is offset by a high risk of losing the investment entirely; for Z, there is a modest amount of risk involved. If you can’t afford to lose any money, then investment X would be the way to go. If you have enough assets to take a chance, then investment Y would be worthwhile. In particular, if a large company routinely makes many such investments, then in the long run there will occasionally be such enormous gains that the company is willing to absorb many smaller losses. Investment Z represents the middle ground, somewhere between the other two.
